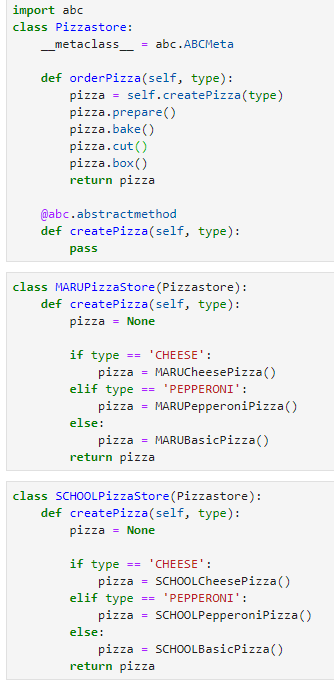
안녕하세요 Dibrary입니다. 이번에는 디자인 패턴 중에 '팩토리 메서드 패턴'을 정리해보겠습니다. 단어에 '팩토리'라는 뜻은 말 그대로 factory 즉, '공장'이죠. 공장은 뭐하는 곳이지 아시죠? 주로 물건을 생산하죠. 이름을 보면 생산의 대상이 메서드인 것처럼 보입니다. 팩토리 메서드 패턴은 인터페이스는 부모클래스에서 정하지만 구체적인 객체 생성은 자식클래스에서 생성하는 것입니다. 즉, 객체 생성 처리를 서브클래스로 분리해서 처리하게 하는 것이죠. 제가 느낀 바로는 결국 초반 인터페이스는 코드가 여러 개로 쓰이지 않고, 하나로 작성한 후에 실질적으로 다형성이 필요한 부분에서 자식 클래스를 어떤 것을 선택하느냐에 따라 다른 결과를 내보이는 것으로 생각했습니다. 많이 드는 피자집 예시를 보겠습니다...