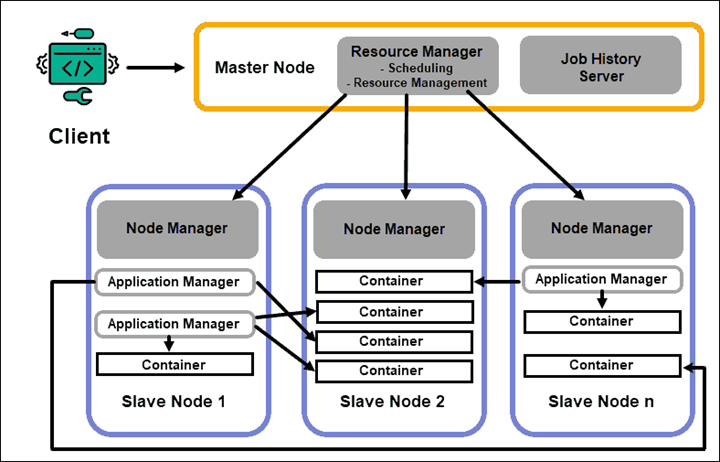
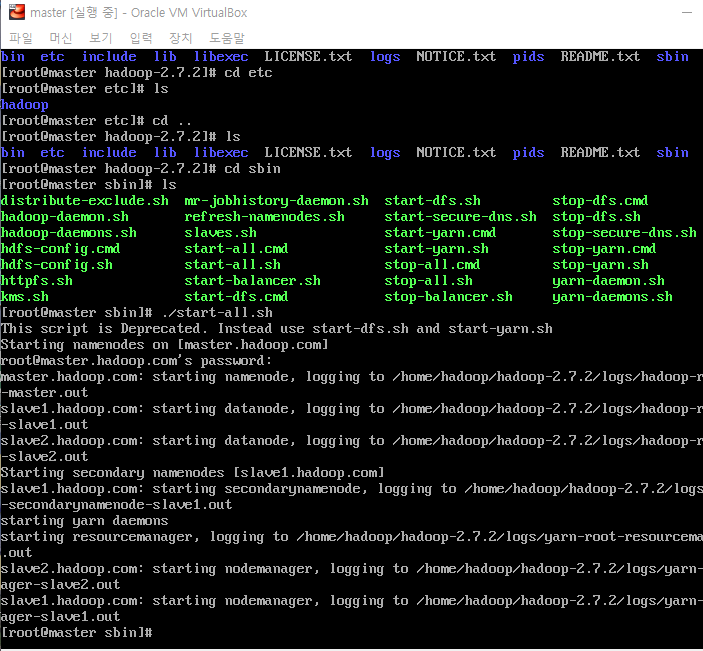
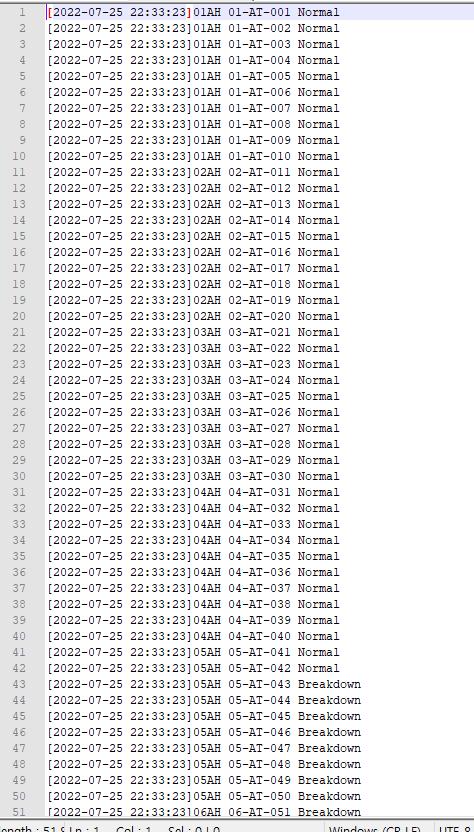
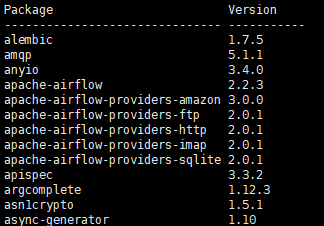
안녕하세요 Dibrary입니다. 앞으로 차츰 이 책의 내용에서 주관적으로 중요하다 생각되는 개념을 정리함과 동시에 '제 생각'도 같이 정리해 둘 예정입니다. 클라우드 데이터 플랫폼 = 모든 유형의 데이터를, 거의 무제한의 장소에서 비용효과적인 클라우드 네이티브 방식으로 수집, 통합, 변환, 분석, 관리되는 데이터 플랫폼 무슨말인가 하면, 데이터가 들어오는 것 부터 사용하는 단계까지 모두 클라우드에서 사용하는 것을 의미한다. 데이터 관련 기술을 처음 접하기 시작하면 대부분 로컬에 VM등을 사용해서 여러 PC환경을 갖춘 후에 실행해봐야 하는 경우가 대부분이다. 이런 거 말고 그 단계를 클라우드에 있는 걸 사용하거나 한다는 말. 단일 시스템 아키텍처는 유연성이 크게 떨어진다. ETL (혹은 ELT) 각 단계별..