안녕하세요 Dibrary입니다.
이번에는 Flume을 이용해서 Hadoop에 데이터를 보내보겠습니다.
참고로 Flume은 아래와 같이 설치하실 수 있습니다.
[Flume] 데이터 로그 수집기 플룸, 설치하기
안녕하세요 Dibrary입니다. 이번에는 Apache Flume을 설치해보겠습니다. Flume은 로그 같은 데이터를 수집할 때 사용하기 좋은 툴 입니다. 아주 간단하게 주요 컴포넌트를 소개하자면 Source / Channel / Sink
dibrary.tistory.com
데이터를 보내기 위해서는 당연하게도, Hadoop cluster는 실행 중이어야 합니다.
먼저, 제가 사용한 Flume 버전은 1.9.0이고, Hadoop 버전은 2.7.2 입니다.
Hadoop cluster에서 namenode가 있는 위치는 192.168.56.114 였습니다.
먼저 임의의 데이터를 준비해 뒀습니다.

뭔진 몰라도 꽤 많죠? 한 80만줄 되었었는데, 저는 결과를 좀 빨리 보고 싶어서 2000줄로 줄여놨습니다.
이 데이터는 Flume이 읽어들이는 폴더에 넣을 데이터 입니다.
먼저 Flume을 설치하셨다면 아래의 폴더 및 파일들을 보실 수 있습니다.
여기서 conf로 이동해 주시면 아래의 내용들이 보입니다. 참고로 Test_Agent.conf는 제가 만든거니까 없으실거에요.

저는 Test_Agent.conf라는 파일을 만들었습니다.

내용은 별거 없고, 그저 Source에서 얻은 데이터를 hdfs sink로 보내는 것이죠.
여기서 path는 Hadoop cluster의 namenode가 있는 위치로 정해주시고, /input이라는 폴더는 hdfs dfs -mkdir /input 명령어를 사용해서 Hadoop cluster에 제가 미리 만들어 놓았습니다.
그리고 conf 폴더 안에 있는 flume-env.sh.template 파일을 복사해서 flume-env.sh 파일을 만들어 줍니다.
저는 flume-env.sh 파일을 아래와 같이 수정했습니다.
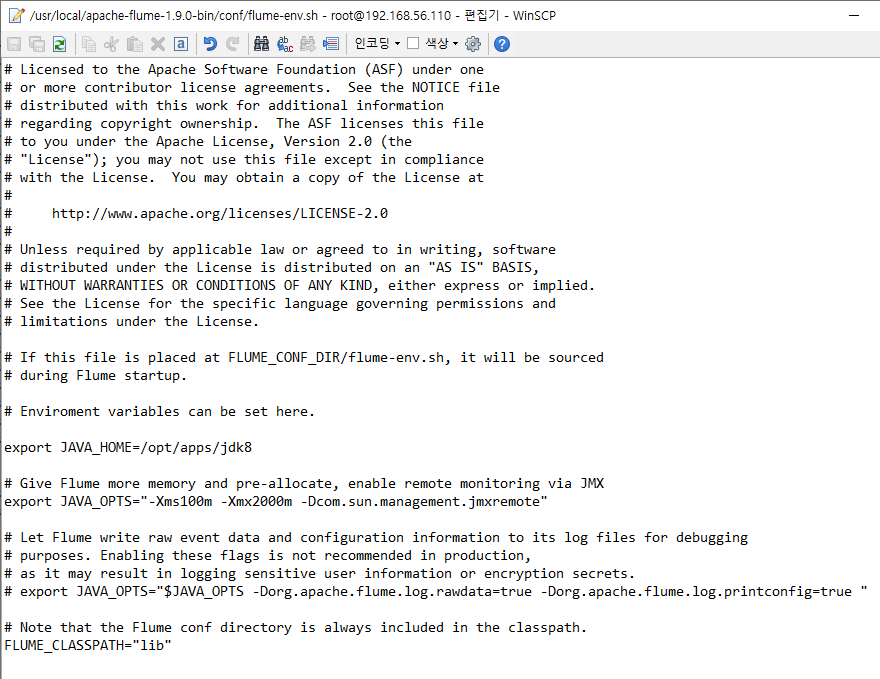
뭐뭐 많은데, JAVA_HOME하고, JAVA_OPTS, FLUME_CLASSPATH 이 3가지만 주석을 풀고 적어줬습니다.
JAVA_OPTS는 기존에 이클립스나 STS등을 써본 분이라면 어느정도 익숙하실 겁니다.
설정은 끝났습니다.
실행 명령어는 flume 경로에 가셔서 ./bin/flume-ng agent -c conf -f conf/Test_Agent.conf -n Test_Agent -Dflume.root.logger=INFO,console 이렇게 해 주시면 막 뭔가가 올라갑니다. (띄어쓰기 및 점 위치를 주의하세요)
어느정도 글자가 막 올라가다가 멈추면 flume이 실행 된 것입니다.
아까 Test_Agent.conf 파일에서 우리는 /home/pilot-pjt 라는 폴더에 데이터를 flume이 읽게 설정해 두었습니다.
해당 파일을 넣게되면 파일은 사라지고, flume이 읽어들어갑니다.
근데 아래와 같은 에러가 나실 수도 있습니다.

아주 그냥 주저리주저리.. 많죠? 이 내용은 라이브러리가 없다 뭐 이런 얘기인데요.
저는 Hadoop-2.7.2/share/Hadoop/common/lib 안의 모든 jar파일을 flume에 있는 lib 폴더 안으로 다 넣어주었습니다.
그리고, 파일이름은 같은데 버전만 다른 경우 예전 버전을 삭제 했습니다.

이렇게 lib안에 다 넣어주시면 됩니다.
그 뒤에 flume을 종료하고, 재시작 하면 됩니다.
아까 만든 파일을 /home/pilot-pjt 폴더에 넣고 확인해보니 임의로 넣은 데이터가 잘 전송된 것처럼 나옵니다.

Hadoop cluster에서 hdfs 명령어로 input폴더를 확인해보니

위에 로그에 찍힌 파일 이름과 똑같은 파일이 들어있는 것을 확인할 수 있었습니다.
내용은 아래와 같이 원본 파일 데이터의 일부가 들어있었습니다.

'프로그래밍 > Data process' 카테고리의 다른 글
| AWS - S3 프리티어로 사용해보기 (버킷생성) (0) | 2022.09.15 |
|---|---|
| Python을 이용해서 HDFS의 파일 읽어오기 (0) | 2022.08.17 |
| CentOS 에서 Airflow 설치할 때 주의점 (2) | 2022.07.22 |
| RabbitMQ를 사용해서 데이터를 넣고, 꺼내와 보자 (0) | 2022.07.20 |
| [공공데이터포털] 사용해보기 (1) | 2022.07.13 |