안녕하세요 Dibrary입니다.
이번에는 트리 알고리즘을 정리해보겠습니다.
먼저 트리라는 자료구조는 하나의 루트로부터 시작해서 계속 가지를 쳐 나가는 것입니다.

이렇게 말이죠. 다만 2개씩만 하는 경우에 한해서 이진트리라고 특별히 이름 짓습니다. (이는 데이터를 빠르게 찾는데 굉장히 유용하기 때문에 알고리즘에서 주로 사용됩니다.)
이 트리형태로 해답을 찾아 나가는데, 각 트리의 노드가 해답을 찾아나가는 '질문'으로 된 것이 결정트리 입니다.

이런 것이죠. 질문이 꼭 하나로만 구성될 필요도 없습니다.
파이썬은 sklearn 모듈을 사용해서 결정트리를 사용할 수 있습니다.
먼저 임의의 데이터를 가져와보겠습니다.
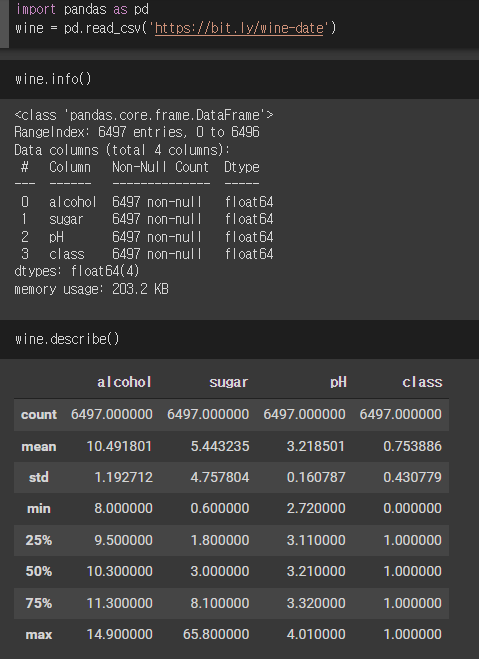
이 데이터 중에 class를 target으로 잡고, 나머지 3가지 항목을 해당 target을 구하는데 필요한 '자료' 즉, 데이터로 분류해봅니다.
당연히, 분류한 후에 훈련 데이터와 학습 데이터를 나누는 홀드아웃 과정도 거쳐야 하구요.

그리고 나눈 데이터를 표준화 했습니다.

이제 이 데이터에 DecisionTreeClassifier 라는 결정 트리 모듈을 사용하면 됩니다. (트리가 뻗어 나가는 깊이를 조절하고자 한다면 max_depth 값을 초기 전달인자로 넣어주시면 됩니다.)

그런데, 우리는 항상 홀드아웃을 이용해서 특정 비율로 데이터를 구분지어 놓았습니다. test_size = 0.2라고 전달인자를 넣었다면, 해당 데이터 100을 기준으로 훈련 데이터는 80, 검증 데이터는 20 이렇게 구분한 것이죠.
근데, 이렇게 하면 사실 '전체 데이터'에 대해 훈련했다고 보긴 어렵죠. 또한, 검증데이터도 한정적이어서 전체를 대변한다고 하기도 어렵습니다.
그래서 그나마 이러한 문제를 보완한 것이 '교차 검증'입니다.

보시면, 2대8로 나눈 것을 한번만 하는 게 아니라, 각 데이터 모두가 될 수 있게 번갈아서 하는 것이죠.
이렇게 하면 데이터 전부를 확인한 셈이 되므로 좀 더 데이터에 맞는 '결과'가 나오게 되는 것이죠.
'프로그래밍 > Python' 카테고리의 다른 글
| 파이썬으로 구현해 확인하는 MODBUS통신 - Client 편 (5) | 2022.08.05 |
|---|---|
| REST 테스트를 하기 위한 json-server 실행하기 (0) | 2022.08.01 |
| [혼공머신러닝] 4장 로지스틱회귀 정리 (0) | 2022.07.23 |
| 파이썬으로 XML파일 파싱해서 사용하기 (0) | 2022.07.18 |
| [혼공머신러닝] 3장(최근접 이웃회귀, 선형회귀) 정리 (0) | 2022.07.15 |