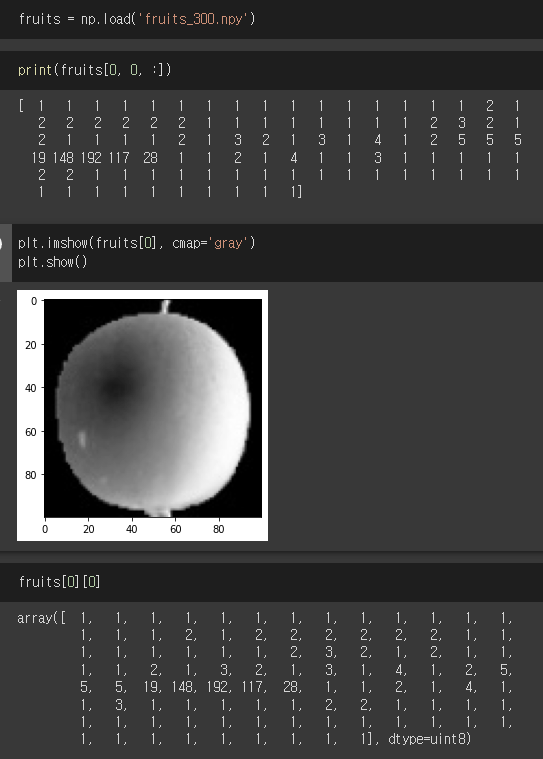
안녕하세요 Dibrary입니다. 이번에는 혼자공부하는 머신러닝의 6장 내용인 'k평균 알고리즘'에 대해 정리해보겠습니다. k평균 알고리즘은 아래와 같이 동작합니다. 무작위로 k개 클러스터의 중심을 정합니다. 각 샘플에서 가장 가까운 클러스터의 중심을 정합니다. 그게 곧 해당 클러스터의 샘플이 됩니다. 클러스터에 속함 샘플의 평균값으로 클러스터의 중심을 변경합니다. 클러스터 중심에 변화가 없을 때 까지 2번으로 돌아가서 반복합니다. 즉, 한 마디로 '인접 요소를 가장 잘 대변하는 점 하나를 찍고, 그게 맞으면 평균점이 되는데, 그게 아니라면 평균점이 될 때까지 이걸 반복한다' 는 것이죠. 파이썬은 굉장히 편리하다고 느끼는 게, 이 k평균 군집 역시 파이썬 sklearn 모듈을 사용해서 할 수 있습니다. 먼..