안녕하세요 Dibrary입니다.
이번에는 혼자공부하는 머신러닝의 6장 내용인 'k평균 알고리즘'에 대해 정리해보겠습니다.
k평균 알고리즘은 아래와 같이 동작합니다.
- 무작위로 k개 클러스터의 중심을 정합니다.
- 각 샘플에서 가장 가까운 클러스터의 중심을 정합니다. 그게 곧 해당 클러스터의 샘플이 됩니다.
- 클러스터에 속함 샘플의 평균값으로 클러스터의 중심을 변경합니다.
- 클러스터 중심에 변화가 없을 때 까지 2번으로 돌아가서 반복합니다.
즉, 한 마디로 '인접 요소를 가장 잘 대변하는 점 하나를 찍고, 그게 맞으면 평균점이 되는데, 그게 아니라면 평균점이 될 때까지 이걸 반복한다' 는 것이죠.
파이썬은 굉장히 편리하다고 느끼는 게, 이 k평균 군집 역시 파이썬 sklearn 모듈을 사용해서 할 수 있습니다.
먼저 데이터를 불러와보겠습니다. 저는 책의 내용을 따라 colab에서 데이터를 다운 한 것이므로 아래와 같이 했습니다.

만일 자체 Jupyter를 사용하거나 기타 파이썬 IDE를 사용 중이시라면, Kaggle에서 직접 다운 받을 수도 있습니다.
먼저 받은 데이터를 확인해 보겠습니다. 0번 즉, 첫 번째 데이터는 아래와 같이 확인해볼 수 있습니다.
데이터는 2차원 배열꼴로 되어 있는 것을 알 수 있죠. 각 숫자는 해당 '픽셀'의 색상 값을 나타냅니다. 0부터 255까지의 숫자중 하나의 값입니다.
일일이 숫자를 바꿔가며 확인한 결과, 0~99까지는 사과가 나오고 100번부터 파인애플로 바뀝니다.
데이터 확인은 끝내고, 데이터의 픽셀값을 분석해보겠습니다.
위 코드에서 앞에서 100장은 사과, 그 다음 100장은 파인애플, 그 다음 100장은 바나나 이미지 데이터가 있는 것입니다.
reshape를 이용해서 (100, 10000)크기의 데이터로 변경 되었습니다. 즉, 100개가 있는데, 각 데이터는 100*100 배열 꼴이 아니라 그냥 10000개의 데이터가 있는 꼴로 되었다는 것이죠.
이 데이터들의 평균값을 시각적으로 확인해보겠습니다.
banana는 평균치가 대략 20~60사이에 있고, apple과 pineapple은 어느정도 겹치는 구간이 있는 걸 보실 수 있습니다.
여기서 잘 생각해보면, 평균을 기점으로 banana인지, 아니면 다른 것 (apple이거나 pineapple)인지를 알 수 있겠죠?
이번에 소개할 'k-평균 알고리즘'은 바로 이 '평균'을 주어진 데이터로부터 구합니다. 누가..? 컴퓨터가요.
라벨을 보면 0, 1, 2 숫자로 구분이 됩니다. n_clusters를 3으로 줘서 그렇습니다.
fit에서 실제 연산이 수행됩니다. 그 결과,

array값은 111, 98, 91로 나오는데, 이는 0은 111개, 1은 98개 2는 91개로 판단했다는 것이죠.
label이 0인 것을 그려보면

이렇게 나오는데, 사실 거진 대부분은 파인애플이지만, 아닌게 몇 개 섞여있죠. 이런 경우에는 평균을 다시 구하게 해야 합니다. 다른값을 볼까요?

사과만 나와있네요. 이건 잘 분류되었네요.
즉, 이렇게 확인해봄으로써 0, 1, 2 중에 어떤 것은 잘 분류되고, 어떤 것은 좀 애매하게 했다는 것을 알 수 있습니다.
fit으로 훈련을 시킨 후에는 predict로 데이터를 주면 훈련된 정보를 토대로 판단합니다.
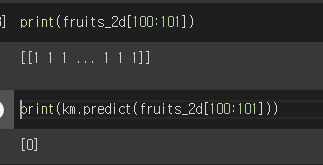
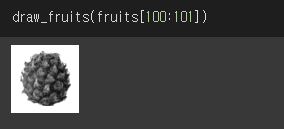
100번째 데이터를 주니 label을 0이라고 판단하네요, 이미지를 확인해보니 아까 우리가 확인한 파인애플이 맞네요.
나름 최적의 군집 갯수를 확인해 보는 방법으로 아래의 코드가 있습니다.
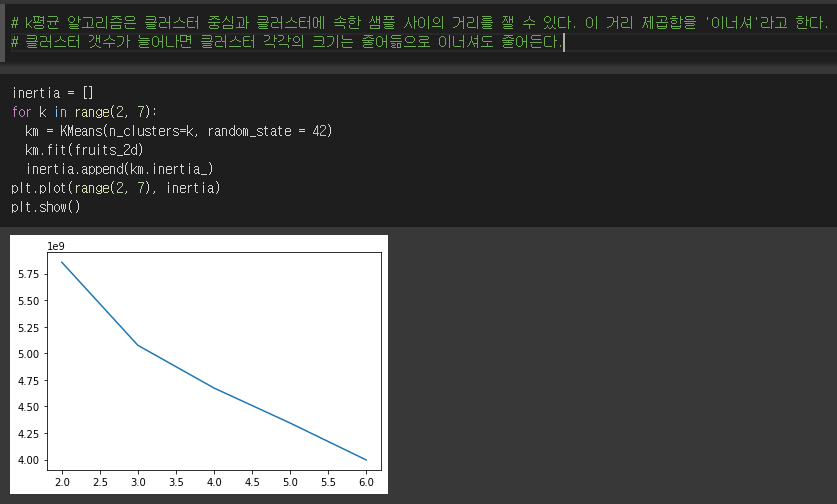
즉, k값을 바꿔가면서 inertia라는 값을 저장하고, 해당 값을 차트로 그려본 것입니다. 여기서 inertia라는 값은 클러스터의 샘플과 클러스터 평균 중심과의 거리 값입니다.
그래프에서 갑자기 꺾이는 부분에서는 클러스터 갯수를 높여도 밀집된 정도가 개선되지 않습니다.

'프로그래밍 > Python' 카테고리의 다른 글
| 파이썬으로 정규표현식 다뤄보기 - 1 (0) | 2022.08.24 |
|---|---|
| [혼공머신러닝] 7장 인공신경망 기본 정리 (0) | 2022.08.20 |
| 파이썬으로 구현해 확인하는 MODBUS통신 - Client 편 (5) | 2022.08.05 |
| REST 테스트를 하기 위한 json-server 실행하기 (0) | 2022.08.01 |
| [혼공머신러닝] 5장 트리 알고리즘 정리 (0) | 2022.07.28 |