안녕하세요 Dibrary입니다.
이번에는 신경망 코드를 정리해보겠습니다. keras는 저도 안써봤었는데, 이번에 알고 꽤나 쉬울 수도 있겠다는 생각이 드는 좋은 라이브러리입니다.
해당 코드는 fashion_mnist 데이터를 사용했습니다. 데이터를 불러오는 코드는 아래와 같습니다.

정말 심플하죠? 핵심은 keras.datasets.fashion_mnist.load_data( ) 입니다.
꼭 fashion_mnist로 하지 않아도 되긴 합니다. 살펴보면, boston_housing 데이터도 있고, cifar10 등등 하나만 있는 것은 아닙니다.

데이터 크기를 확인해보면 아래와 같습니다.
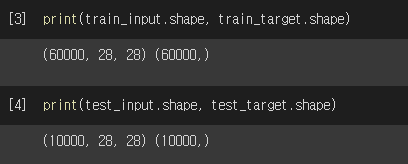
(60000, 28, 28) 에 의미는 28*28 크기로 구성된 데이터가 6만개 있다는 의미입니다.
즉, 하나의 데이터는 28*28 (곱하면 784가 됩니다.)개의 숫자 데이터로 이뤄져 있는 셈이죠.
뭔소린가 의아하다면, 직접 한개를 확인해 보겠습니다. 데이터가 무지하게 많이 나오죠. 잘 보시면, 한 줄은 28개의 숫자가 들어있고, 그 줄이 28개 있습니다.


그럼 이 데이터를 이제 한 줄의 데이터로 만들어 보겠습니다. (그래야 좀 다루기가 편하겠죠?)
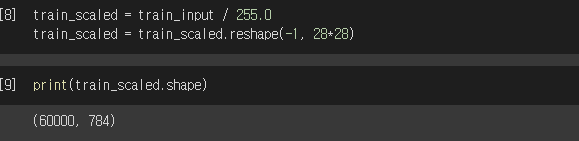
위 코드에서 train_input을 255로 나누는 것은 해당 데이터를 구성하는 숫자가 0~255값인데, 이를 0~1 사이의 값으로 변경하는 것입니다. (번외로.. 이러한 기법은 양자역학에서도 주로 사용합니다.)
그 뒤에 reshape를 이용해서 28*28 = 784개의 숫자 데이터가 하나의 데이터를 구성하게 만들었습니다.
reshape 전에는 28행, 28열로 구성된 데이터가 6만개였다면, 이제는 1행 784열로만 구성된 데이터가 6만개인 셈입니다.
데이터에 대한 탐색은 끝났으니 본격적으로 신경망 모델에 적용해보겠습니다.
먼저 데이터를 훈련 데이터와, 테스트용 데이터로 나눠야 합니다. 주로 사용하던 train_test_split 함수로 홀드아웃을 해 줍니다.


이렇게 하면 6만개의 데이터가 48000개와 12000개로 나뉩니다. test_size를 20%(0.2)로 설정했으니까 딱 맞게 나왔네요.
여기부터가 중요한 코드입니다.

Dense 클래스로 dense라는 이름을 가진 밀집층을 만드는 코드 입니다. 관련 유닛(뉴런)은 10개로 지정했고(10개의 아이템을 분류하므로), 활성함수는 softmax 함수로 했습니다.
input_shape는 입력할 데이터의 크기인데, 우리는 아까 1행 784열로 만들었으므로 해당 정보를 그대로 입력하면 됩니다.
(해당 데이터를 print로 확인해 보면 (784, ) 로 나옵니다. 그 값을 그대로 넣어주면 됩니다.)
그리고 해당 밀집층을 모델로 만듭니다. Sequential 클래스에 전달인자로 넣어만 주면 해당 객체가 곧 모델이 됩니다.

해당 모델을 훈련하기 전에 몇 가지 설정을 합니다. 그 중에 loss라는 손실함수 설정과, metrics라는 부분에 정확도를 같이 볼 수 있게 'accuracy' 값을 넣어줬습니다.
손실 함수는 sparse_categorical_crossentropy 인데, 이는 '정수로된 타겟값만을 사용해 계산하는 크로스 엔트로피 손실함수' 입니다.
여기까지 모델 만들기가 끝난겁니다. 정말 쉽죠? 사실상 데이터 분류 후에 3~4줄만 작성하면 되는 것이었습니다 ;;
만들어진 모델은 fit 함수로 훈련을 시키면 됩니다.

각 step마다 accuracy가 높아지는 것을 볼 수 있습니다. 정확해지는 것이죠.
혼공머신 미션.

'프로그래밍 > Python' 카테고리의 다른 글
| [디자인 패턴] 팩토리 메서드 패턴 (0) | 2022.08.25 |
|---|---|
| 파이썬으로 정규표현식 다뤄보기 - 1 (0) | 2022.08.24 |
| [혼공머신러닝] 6장 k평균 알고리즘 정리 (0) | 2022.08.12 |
| 파이썬으로 구현해 확인하는 MODBUS통신 - Client 편 (5) | 2022.08.05 |
| REST 테스트를 하기 위한 json-server 실행하기 (0) | 2022.08.01 |