안녕하세요 Dibrary입니다.
저번에 만든 AWS S3에 파이썬을 사용해서 파일을 넣고, 꺼내보겠습니다.
이번에 할 파일은 CSV파일로 간단히 해 볼건데, 주의할 점은 각 행마다 column갯수가 같아야 합니다. 즉, 각 행마다 콤마 갯수가 같아야 하는 것이죠. 다르면 어떻게 되냐구요?

이런 tokenizing data 에러를 마주할 수 있습니다.
파이썬으로 AWS를 연동하고 싶으면 boto3 모듈을 설치해야 합니다. 찾아보니 boto3는 AWS를 사용하게 해 주는 SDK라고 합니다.
그리고 aws_access_key_id와 aws_secret_access_key를 가지고 있어야 하는데, 이는 보안이 굉장히 중요하므로 별도로 저는 만들어서 사용했습니다.
위 코드에서 제것의 값은 가렸습니다. 해당 함수를 불러서 반환값만 이용하면 편하겠죠?
그럼, S3를 쓸 때 aws_access_key_id와 aws_secret_access_key는 어디서 확인하냐~ 가 문제네요.
우선 AWS 대시보드에서 '보안 자격 증명'으로 갑니다.
그러면 아래와 같은 화면이 나오는데 여기서 '액세스 키'를 들어갑니다.
저는 이미 만들어서 아래와 같이 나옵니다. 만들지 않은 분들은 '새 액세스 키 만들기'를 누르시면 키가 생성됨과 동시에 csv파일 하나가 다운로드 됩니다.
이 csv파일에 있는 정보를 아까 파이썬 코드의 aws_access_key_id와 aws_secret_access_key에 입력하시면 됩니다.
먼저 버킷의 해당 '폴더'에 무엇무엇이 있는지 확인해보겠습니다.
위 코드는 s3라는 이름으로 client객체를 생성하고, 해당 객체를 이용해서 logs/폴더 내의 objects들을 가져옵니다.
print로 확인해보면 저는 아래와 같이 나옵니다. 만일 에러가 난다면 정상적으로 읽지 못한 것입니다.
그럼 그 중에 파일 하나의 '데이터'를 직접 보겠습니다.

s3 객체는 기존코드와 같고, Bucket 부분만 가려놓았습니다. Key에는 logs폴더 내의 status_data.csv파일을 읽어오겠다는 것입니다. (Key는 반드시 대문자로 시작해주셔야 합니다. key로 하면 실행이 안됩니다.)
결과는 아래와 같습니다.
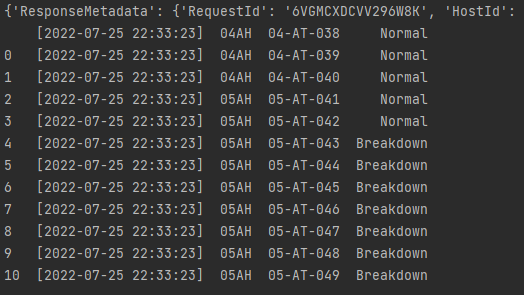
네 실제 데이터와 같습니다.
그럼 파일데이터를 S3에 올려보겠습니다.

아까와 같이 s3객체는 그대로 같고, upload_file이라는 메서드를 사용하면 됩니다. (이번에도 버킷 이름은 가렸습니다.)
올린 후에 AWS 대시보드를 통해 확인할 수 있습니다. (아니면 아까 list_objects를 사용해서 확인할 수도 있습니다.)
'프로그래밍 > Data process' 카테고리의 다른 글
| Hadoop 기본 구조 및 원리 (2) | 2022.09.23 |
|---|---|
| Kafka 기본 개념 및 아키텍처 (0) | 2022.09.22 |
| AWS - S3 프리티어로 사용해보기 (버킷생성) (0) | 2022.09.15 |
| Python을 이용해서 HDFS의 파일 읽어오기 (0) | 2022.08.17 |
| Flume으로 Hadoop에 데이터 보내기 (0) | 2022.07.29 |