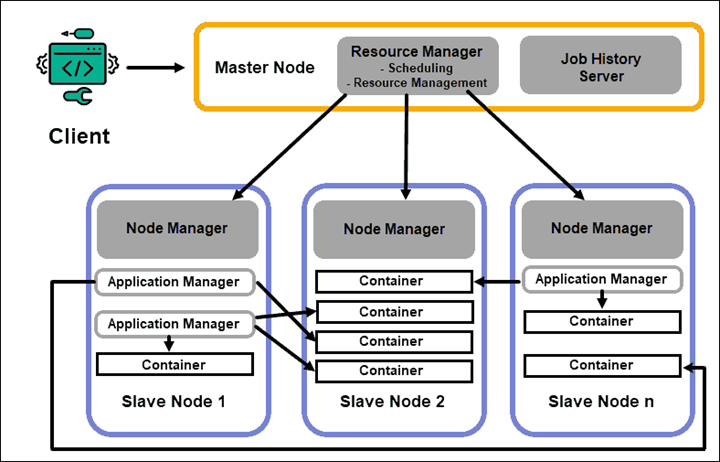
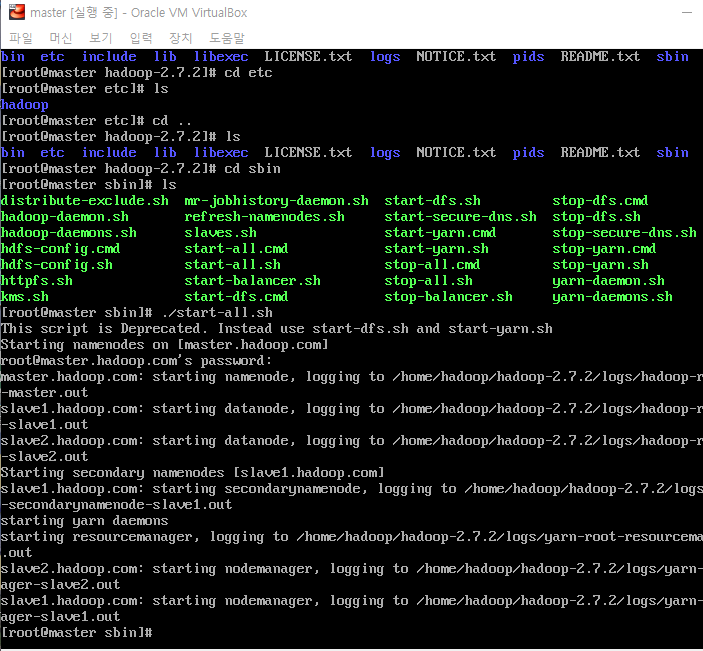
안녕하세요 Dibrary입니다. 하둡은 조금 검색만 해도 수두룩히 많은 내용이 나오는 클러스터로 분산 저장, 처리를 할 수 있게 해 주는 프레임워크죠. 제 나름대로 이해하고 찾은 내용을 여기에 정리해보겠습니다. 처음 접하는 분들에게 도움이 되었으면 좋겠네요. 하둡의 특징 1. 데이터를 Block 단위로 나눠서 저장한다. (분산 저장 가능) 2. Scalability하다. 즉, 클러스터에 Node가 더 필요하면 추가하거나 줄일 수 있다. 3. 처리하던 Node가 실패하면, 다른 Node로 작업을 할 수 있다. 간단하게 보면 위와 같은기능을 가지고 있습니다. 그럼 이 기능들이 어떻게 동작할 수 있는지 보죠. 하둡은 크게 Version1과 Version2로 나눌 수 있습니다. (Version3이 최근거지만, ..