Python을 이용해서 HDFS의 파일 읽어오기
안녕하세요 Dibrary입니다.
이번에는 제가 하둡 클러스터에 올린 파일을 파이썬으로 읽어보겠습니다.
참고로 사용하실 파이썬에는 미리 hdfs 라이브러리가 있어야 하므로 pip install hdfs 를 해 주세요.
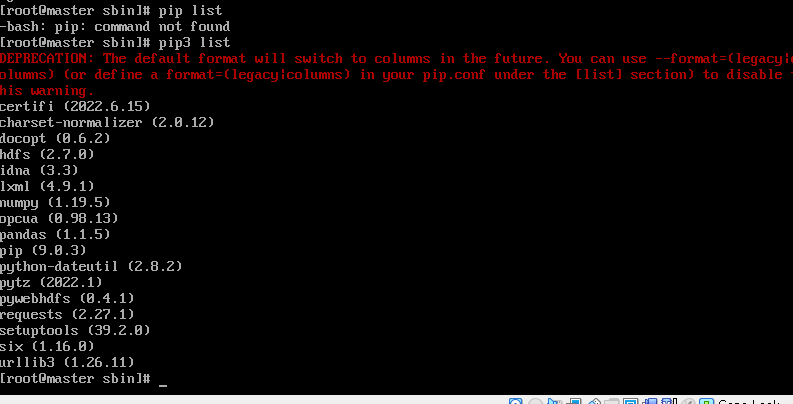
제가 사용한 hdfs 버전은 2.7.0 이네요.
해당 라이브러리를 더 상세하게 익히고 사용하고자 하는 분들은 아래 사이트를 참고해주세요.
API reference — HdfsCLI 2.5.8 documentation
Parameters: url – Hostname or IP address of HDFS namenode, prefixed with protocol, followed by WebHDFS port on namenode. mutual_auth – Whether to enforce mutual authentication or not (possible values: 'REQUIRED', 'OPTIONAL', 'DISABLED'). max_concurrenc
hdfscli.readthedocs.io
는 하둡을 virtualBOX로 실행해 놓았습니다. 각 virtualBOX는 centos 7 버전을 사용하고있고, 하둡은 2.7.2 버전을 사용했습니다.

먼저 HDFS 내부에 폴더는 아래와 같이 5개가 만들어져 있네요.

이 중에서 저는 webhdfs 안에 있는 test.txt 파일을 읽어오고자 합니다.

아주 간단한 내용을 넣어놓은 파일이죠.
읽어오는 코드는 아래와 같습니다.

그저 client라는 hdfs 접속 객체를 사용해서 /webhdfs/test.txt 파일의 내용을 읽어서 확인하는 것입니다.
test string이라는 내용이 들어있었네요,
그럼 굉장히 큰 파일은 어떨까요? 아래에 있는 this_datas 라는 파일을 보면 size가 458.89MB로 굉장히 큽니다.

큰 파일이라 할 지라도 읽어올 수 있습니다.

실제 파일 안의 데이터도 위와 같습니다.
코드에 chunk_size를 지정하면 읽어온 내용은 generator가 됩니다.
그래서 읽어온 내용에 for문을 사용해서 다시 확인하는 작업을 해 줘야 하죠. 아래 코드는 chunk_size를 20으로 지정한 후에 읽어온 모습입니다.